
 This is another post about how grateful I am for our current architecture of our systems. It’s not perfect but boy does it work well for us on many an occasion.
This is another post about how grateful I am for our current architecture of our systems. It’s not perfect but boy does it work well for us on many an occasion.
Sometimes one of the scariest things that can happen to your business is too much success. Since the start of WEF we’ve been having that feeling a bit with our site ShowGroundsLive.com. Don’t get me wrong, I’m thrilled to see so many people using our site and getting vital show information from it, but as that’s happening we’re also seeing our computing resources getting squeezed. The last thing any business wants is to not be able to meet demand.
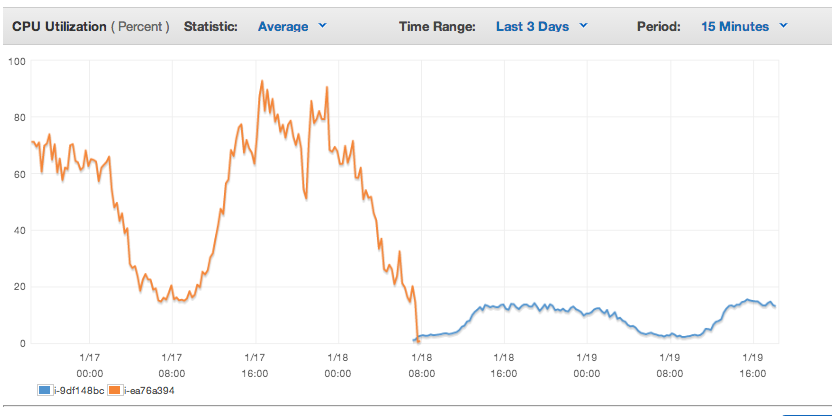
Our site traffic has been up about 50% year over year and seemed to be building with each successive day bringing more traffic than the day before. Friday I noticed our servers pushing hard, reaching 80% capacity several times throughout the day. Late in the day we were pushing uncomfortably close to that 100% capacity. I didn’t have any fundamental concern that we couldn’t handle the scaling issues, but could we address them quickly enough that no one would even know we were getting close to capacity in terms of delivering web pages quickly to our customers.
Fortunately as I reached out to my team we were able to come up with the most obvious and quickest solution to the problem. Because we host our web-application environment on Amazon’s cloud architecture, we were able to simply replace our virtual servers with faster more powerful servers. Early Saturday morning we moved our primary web servers to higher capacity server and achieved instantaneous results.
The graph at the top of the page shows our primary web server’s CPU utilization through the transition. It goes from flirting with 100% most of the day Friday to not breaking a sweat at 15% all day saturday. Thanks to the cloud gods.
